
Before implementing or adopting cloud technology, it is important to understand the cloud and what options you have when thinking about your deployment.
Let’s start with the basics: What is cloud computing?
Cloud computing delivers on-demand computing services — from applications to storage and processing power — managed virtually on a pay-as-you-go model. Companies can rent access from a public cloud provider instead of directly owning and managing computing infrastructure or data centers. This allows firms to avoid the upfront cost and complexity of managing their environment and simply pay for what they use when they use it. Learn more about the advantages of the public cloud.
Breaking down the cloud ecosystem
It is important to understand the core concepts of cloud computing and how it can help your business. Several computers, servers and data storage equipment make the cloud of computing services in a cloud computing ecosystem. The shared responsibility model helps to break down which the cloud provider and self-managed handle services.
Shared responsibility
In the cloud’s early development period, there were concerns about data security in multi-tenant architectures, and in infrastructures outside of the business’ control. Public cloud providers have successfully secured their environments to the point where cloud usage in sectors such as financial services, healthcare and hospitality have increased. The US Central Intelligence Agency has also made the strategic decision to move operations onto the public cloud.
The shared responsibility model displays the security and reliability of cloud providers. In this model, the cloud provider is responsible for the security OF the cloud, while the business is responsible for the security IN the cloud. (See Figure 3 – Shared Responsibility Model)
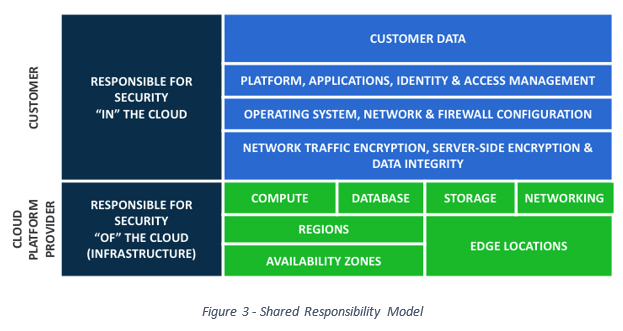
The cloud provider manages and controls the host operating system (OS), the virtualization layer, and the facilities and networks’ physical security. The business configures and manages security controls for the guest OS and their applications, including updates, security patches, firewalls and security groups. The business is also responsible for encrypting data both in transit and at rest.
Storage
- Cloud providers offer storage in multiple forms and costs.
- Ephemeral storage is less costly than highly resilient storage.
- Storing objects that are retrieved in milliseconds is more expensive than archival storage that takes hours to be retrieved.
- Storage that uses solid-state server drives (SSD) costs more than storage that mimics magnetic tape drives (MagTape).
Cloud providers offer a multitude of storage options with built-in archival policies. Typically, a provider configures a system to place new data in storage with immediate access. If the data has not been accessed in 60 days, it is automatically transferred to cheaper, long-term storage. Often, after 365 days, the data will be moved to an off-site archive to save more on storage costs.
One method of bulk import solutions consists of attaching a tractor-trailer to the network, saving the data, then driving it to a data center. Since the data centers are heavily guarded, the business is unable to directly access them. Most consultants working for cloud providers are denied knowledge of and direct access to these data centers to bolster security.
Compute
Moving applications to the public cloud requires computer technology. The public cloud providers call this compute, and several models offer this capability.
- On-demand billing is done by the second with minimums, making it the most expensive model.
- It is possible to reserve instances for an entire year at savings of up to 70% of on-demand costs if the business can commit to the long-term pricing plan.
- A third model places a bid price on unused computing resources to utilize them for the non-essential computing process. In this scenario, a business might need to transform data into a data warehouse after hours. They may place a bid price that purchases unused computing resources at a low cost to transform the data into the warehouse. A confirmation that the data is moving is then sent by a serverless cloud function. If it is not, it deploys on-demand services that move the data before the new day begins. Because this approach is unpredictable, the business needs to design its services to take advantage of the low price while moving important info to compute resources that are always available.
- Consumers can purchase on-demand compute resources that come with specific operating systems. The price of these includes the licenses to use the software. These include Windows, Linux, Windows with SQL Server, Linux with MySQL and many others.
- Compute resources range from 1 CPU with 2 GB memory to 128 CPUs with 3904 GB memory and can often be scaled up in minutes if the resources are available from the cloud provider.
- Cloud providers offer a free tier for training and experimentation.
Auto-scaling
Through a process of elasticity, an individual can add or terminate compute resources automatically based on demand. As demand increases, the cloud will automatically launch more instances to meet the demand up to a configured maximum, then as demand drops, the cloud will automatically terminate instances down to a minimum configured size. Incorporating creative sharing into the database’s design to enable scaling out onto multiple instances makes the database more elastic. The advantage of this elasticity within the cloud is that it enables businesses to pay for a given number of resources and give unused resources back to the cloud provider to use elsewhere.
An application’s design must be able to scale out and back to take advantage of the elasticity. Historically monolithic applications are not architected to do this and require rework before they can leverage this key feature of the public cloud.
Database options
Database servers can be split into two categories:
- Relational databases store data in discrete columns (schema) and are accessible through Structured Query Language (SQL).
- An individual can scale SQL databases vertically (scaled up) by expanding the power (or size) of the hardware serving the database.
- A SQL database is designed for Online Transaction Processing (OLTP) and stores data as fast as possible.
- NoSQL databases have a dynamic schema that is ideally suited for unstructured or semi-structured data.
- NoSQL databases can scale horizontally easily (scaled out) by adding more servers.
A derivative is a Data Warehouse that is specifically designed for reporting and analytics. Once data gets into a data warehouse, it rarely changes or leaves. The data in a data warehouse is organized for reporting. Star and snowflake schemas are popular designs for data warehouses.
Most public cloud providers offer databases where they completely manage scale, high availability and maintenance. These services automatically provide multiple region database performance and reliability.
Queues
As incoming data grows, the ability of the database to ingest this data becomes a concern. The solution is to put the incoming data into a queue or message bus, and have the database retrieve it when it can do so. This enables queues to distribute applications across multiple front-ends, which feed a single queue that feeds the back end-systems.
- The queue creates a fire and forget scenario that allows the front-end application to move on to the next task, while the back-end database can read messages from the queue at its own pace.
- This type of loose coupling allows the system architects to grow the applications despite their bottlenecks without impacting other services.
Content delivery networks (CDNs)
Content delivery networks (CDNs) are delivery services that cache data closest to the user and deliver it from the local cache instead of from the remote server. Their design confirms that they have the most recent data in their cache, and users often utilize them where they expect unpredictable activity. For example, a news website hosted in the US can use a CDN to help report a hurricane approaching Japan. When the user load from Japan increases, the CDN will read the newsfeed in the US once and then deliver it to Japan’s users from a closer cache as needed. There is only one instance where the traffic crossed the ocean. All subsequent requests then deliver from the closest region.
Microservices
Since the introduction of the public cloud, businesses are breaking up their large, monolithic application into smaller components. The smallest of these is a microservice, which is a fine-grained service that can be used on demand. True microservices are independent and self contained. An example of a microservice is an application that scans a PDF file. After scanning the file, the microservice returns a data structure containing discrete data which routes to data storage. The business would only pay for the computing resources used during the time the environment exists.
Many applications reuse microservices via a loosely coupled API. A separate development team can face maintaining and improving the existing microservice solution while staying hidden from the “consumers” of the microservice. Teams can work independently and release their microservices independently without requiring a lot of coordination, enabling faster and more frequent delivery. The service includes the API, business logic and the database.
Data relationships often require services to be designed so that they are “small enough.” Most migrations from monolithic applications reveal some opportunities for true microservices and refactoring for other “small enough” services with dependencies.
DNS routing
The Domain Name System (DNS) is the telephone book of the internet. The network equipment uses IP addresses such as 192.168.1.1 and 24.122.10.28 to find each other. Humans prefer to use aliases such as www.microsoft.com, crosslake.com or Jentech.biz — the DNS servers perform these translations.
Public cloud DNS services take this further by offering routing categories.
- Weighted routing could route traffic in a 50/50, 70/30, or even 1/255 ratio between destinations.
- Latency-based routing sends traffic to the destination with the lowest latency, improving performance and enabling faster response time.
- Geolocation-based routing sends traffic to destinations in a specific location. For example, using a geolocation-based routine, an architect could configure DNS to send all requests from the UK to a UK-based environment, all requests from Saudi Arabia to a different environment and all requests from the rest of the world to a US-based environment.
- It is also possible to restrict the types of data served in each environment, for example, enabling UK data to reside only on UK servers. Often this is required for compliance with local laws.
DNS can use health checks to route traffic around unhealthy environments.
Load balancing
A load balancer routes information to servers based on their ability to process the load when more than two servers are present in a configuration. The load balancer is an intelligent traffic cop that can distribute incoming requests to two or more servers to maintain optimal performance.
- Intelligent load balancing can balance based on different needs.
- Location-based balancing can route traffic to servers closer to the user
- Cross-region load balancing can route traffic to servers located in a different geographic area.
Another feature of most load balancing is health check and management. The load balancer retrieves health data from each server in its configuration and, when the server is unavailable, will automatically remove the server from the pool and route traffic to the remaining fleet. Some load balancers can detect when the unhealthy server has returned and add it back to the pool.
Messaging
Public cloud providers offer messaging services such as email and phone messaging (SMS). Applications use these as needed. This makes public cloud services easy to configure and incorporate into custom applications and distribute the processing load.
Identity and access management (IAM)
Identity and access management (IAM) ensures public cloud security. IAM is the process for identifying, authenticating and authorizing individuals or groups of people to access specific applications, systems or networks by assigning user rights and restrictions.
- Lightweight Directory Access Protocol (LDAP) is a client-server protocol for accessing directory services. It is based on the X.500 specification and runs over TCP / IP networks. The application sends the username and password to the LDAP server, and the server returns the credentials if the login is valid.
- OAuth is a delegated authorization framework that uses REST / APIs. It enables applications to seek limited access to user data without giving away the user’s password. Since it uses REST, it decouples authentication and authorization from the application and supports multiple use cases.
Public cloud providers also offer an IAM service that is used to manage users, permissions and roles. These can be integrated with other identity providers.
Containers
Virtual machines are software instances of a server that include a software-defined network, operating system and disk drive infrastructure. The ability to load hundreds of virtual machines onto a single physical server simplifies deploying fully built solutions in minutes on the same physical hardware. This concept revolutionized the shared hosting environments for both on-premise and the public cloud.
Containers use a common host operating system and isolate solutions at the application level. This creates a far more lightweight deployment since you do not have to deal with a guest operating system on every application. Like virtual machines, containers need infrastructure but in a simpler form.
- Containers can be set up and run on a laptop, then copied to a public cloud for execution.
- They are set up to take advantage of elasticity and can be easily updated.
- Containers have fewer parts requiring ongoing maintenance than virtual machines. They also take up much less disk space because they do not have the operating system baggage.
Containers are not the optimal solution for everything. In environments where you need to run different operating systems, virtual machines may still work better. Containers are a great transition step on your migration to the public cloud.
Serverless
Cloud providers provide serverless offerings that encapsulate the best methods for specific functionality on a transaction level, while removing the need to manage servers, compute resources and storage. Businesses using serverless database connect to the database the same way they connect to their existing database instances.
For example, AWS offers Aurora and Microsoft offers Azure SQL Database Managed Instance. Both are serverless relational database offerings that transfer all the management for updates, performance, scalability, reliability and high availability to the cloud provider.
Public cloud providers offer serverless code engines, such as AWS Lambda and Azure Functions, that run code for virtually any application or back-end service with zero administration. The code engines require zero provisioning or managing servers, so the user only pays for computing time. The service manages everything to run and scale the function with high availability once the code uploads. Then, the code triggers from other services such as a web or mobile app that call on the code.
Other serverless services include computing offerings that let you run microservices and containers; storage options; data offerings including SQL, NoSQL and data warehouse services; integration such as messaging, queueing and analytics; and developer tools. Cloud providers are constantly adding more services to their serverless offerings. Many businesses are getting closer to a no-operations (NoOps) model using serverless services.
Interesting in taking the next steps on your journey to the cloud? Get started with a FREE one-hour assessment today!