
I’m often asked to help people improve the value of their root cause analysis (RCA). Here’s my most common advice. I include a RCA process to improve your software development and advice to make your analysis more effective.
Summary
- When determining the problem, ask why until you hit a people issue.
- Ask what’s the earliest process that could have prevented this. This can be applied to many bugs at once using a drop-down in your bug tracking system.
- Implement more than your first solution.
Background
After a production issue, RCA is the process to get to its root, fix that root cause and make sure it never happens again. The process can be formal or quick and dirty. It can be done for one issue or many at once, but it should never be about finding blame. The ultimate point is for identifying, fixing and preventing.
Identifying the root cause
My favorite technique for determining root cause is the five whys technique. You ask why something happened, and then you ask why that happened, and so on like a 5-year-old. It would be annoying if it weren’t so effective.
The number five is arbitrary — it’s meant to be high enough to keep people asking why and not stopping at the first things. Stopping with the whys too soon is the most significant mistake people make with this technique.
My advice is to keep going till you get past the technical causes to a people cause. The goal isn’t to find someone to blame. While the technical reasons are important, there’s often an underlying people issue.
Let me give the most recent example from a client. They had an outage and did an investigation, which showed that, while they had been trying to implement infrastructure as code (IaC), they also made changes in production outside of the code. When the deployment happened, the production state was not where the code could deal with, and the deployment broke things.
Their RCA found this issue — which is great — but then they stopped. My advice is to take RCA one step further. Why were people not using IaC in production?
- Is it a training issue where the operational changes are made by people who don’t know the code?
- Are the people making different changes under different reporting structures that have different processes?
- Is there an incentive for making changes quickly rather than going through the code path?
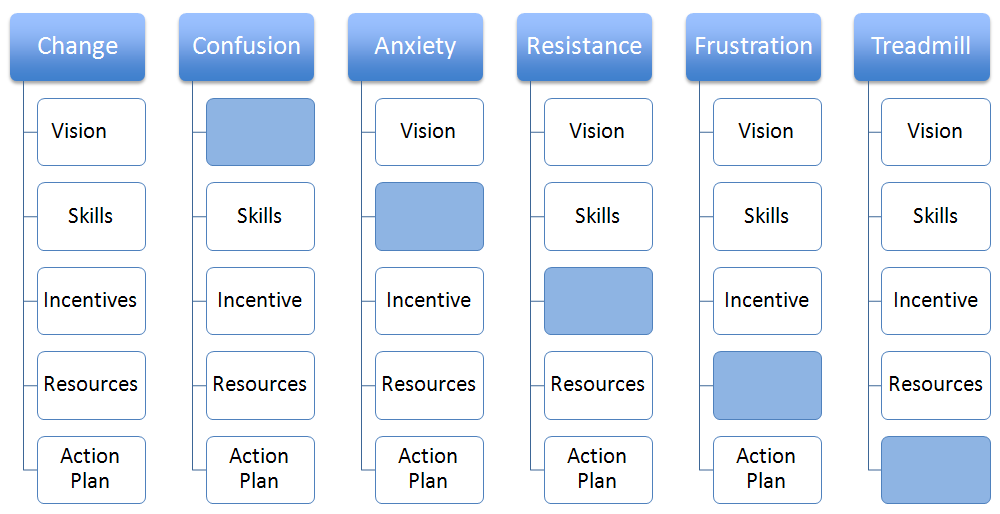
There’s a categorization system called the six boxes approach, which can help identify the people issues.

The Lippett-Knoster approach for change management is another nice model for identifying the people issues.
Fixing the root cause
The biggest problem often resulting from RCAs is not implementing all the fixes. Either the team implements the first or easiest fix or none at all. I often see the same root cause suggestions repeatedly appear on multiple RCAs, which is just a waste of time. If you’ve found it, fix it!
My advice is to do as many fixes that would have prevented the issue as possible. It seems silly to have to say this, but fix it all! There’s a big tendency among people to grab the first or most straightforward solution. Take the time to do several.
Preventing the issue
Let’s look at a method to evaluate many issues to find common problems — then prevent them.
My favorite question for this phase of the RCA is, “What’s the earliest process that could have prevented this?” It might be the most important question in the RCA. Do you need to know the exact cause if you can figure out a way to prevent it?
There’s a simple way to identify that root cause that gives you accurate data to fix your team or company’s software development.
- Add a drop-down on your bug tracking system — Jira, TFS, Salesforce, whatever. In the drop-down, put a bunch of preventions like:
- Requirements from PM
- Acceptance demo and test
- Unit test
- Component / API test
- Integration or resource use test
- A / B test with real customer data
- Deployment automation
- Deployment risk prevention (e.g., canary, blue / green, etc.)
You can change these or add your own but try to start with fewer than ten choices.
2. Review about 100 to 200 high-priority bugs in your system. Definitely look at issues in production and escalated from clients, but also consider ones found internally after merging into main that didn’t make it to production.
Rank the bugs with that drop-down. This is an ugly, manual job and will take a couple of hours, but it’s worth it to do it once every six months to a year. Don’t farm it out to the dev teams. Just get one to three people to go through them all quickly.
3. Look for patterns. Most companies have one or two areas where they are having problems. This exercise gives you the data to prove that those areas need to be fixed.
I’ve seen problems in most of the areas mentioned in the list, except unit testing. Unit testing wasn’t shown to be a significant bug preventative for P1 bugs in the few companies I looked at. I think that’s because it’s better at documenting the code and making it maintainable than preventing bugs.
4. Find subcategories and do another pass. Most companies seem to have one or two major areas where they need help. Unfortunately, the exercise above will have narrowed down the problem but not provided a root cause. It just tells you where to look.
For example, were requirements from PM not translated from epics to stories? Were they not in the acceptance criteria? Were they not validated with customers? Did they not include the client, the problem from the client point of view, and / or the outcome for the client?
You’ll need a new set of categories and another pass of just the bugs in that category to narrow down your root cause among the available issues. In the spirit of 5 whys, you may need several passes to get enough information to go all the way to the root cause. This will sound like a lot of work, and it is, but you are doing a massive RCA for a lot of issues to get actual data on where to fix your software development lifecycle.
Copyright © 2021, All Rights Reserved by Bill Hodghead, shared under creative commons license 4.0